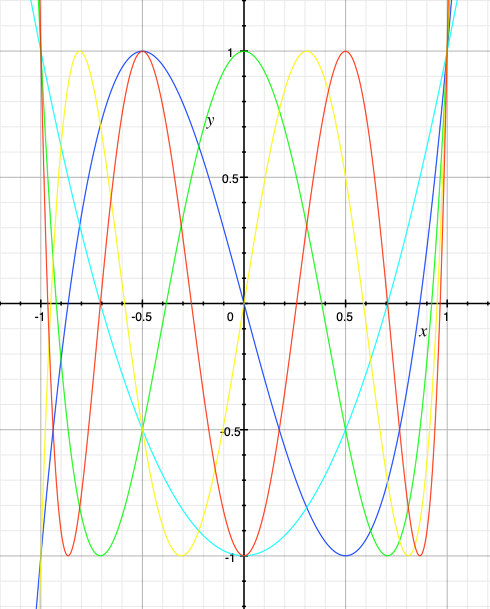
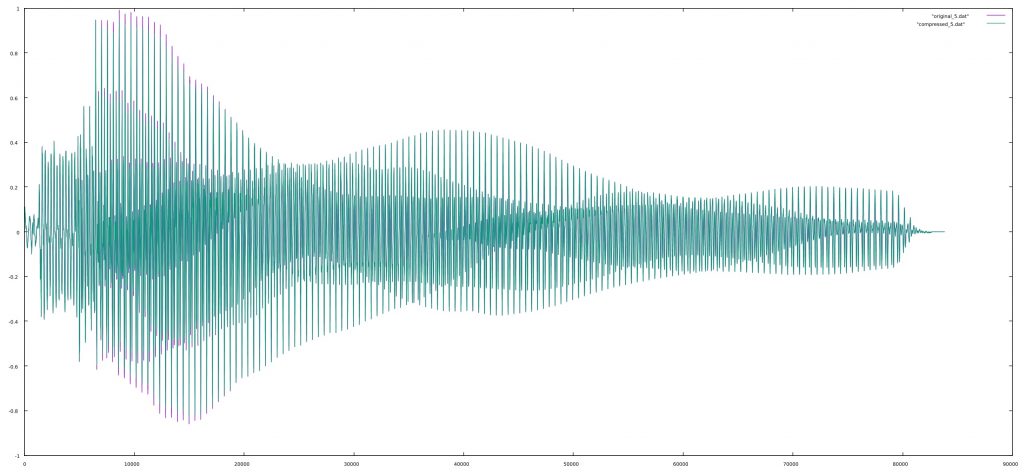
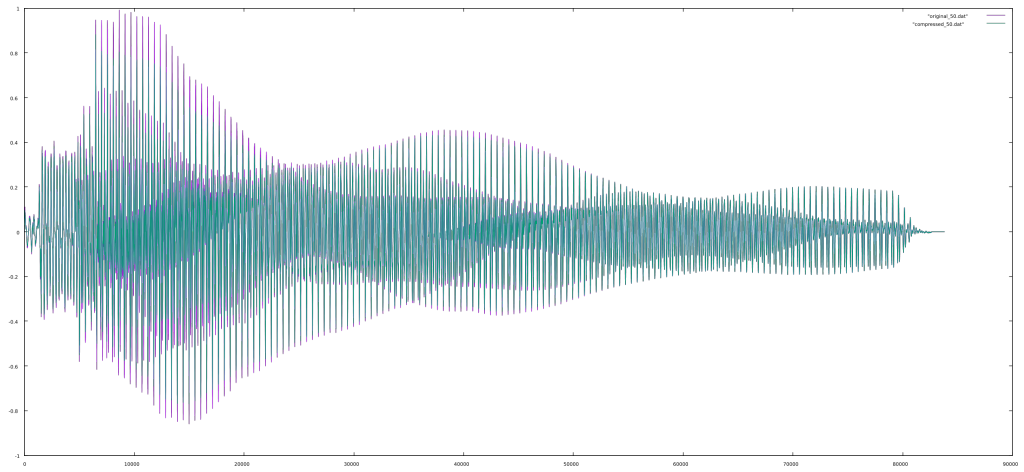
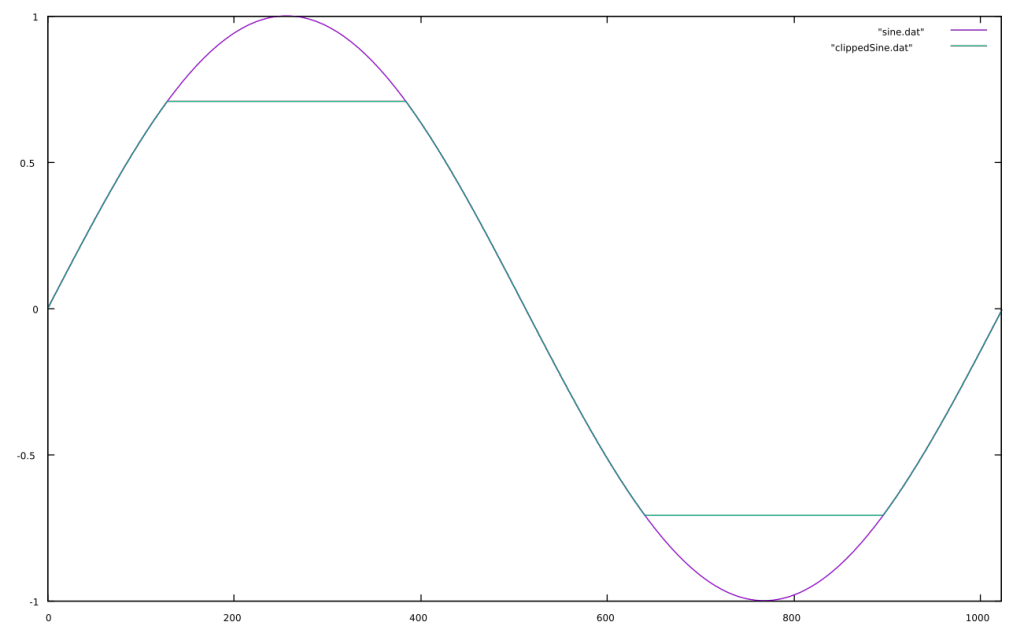
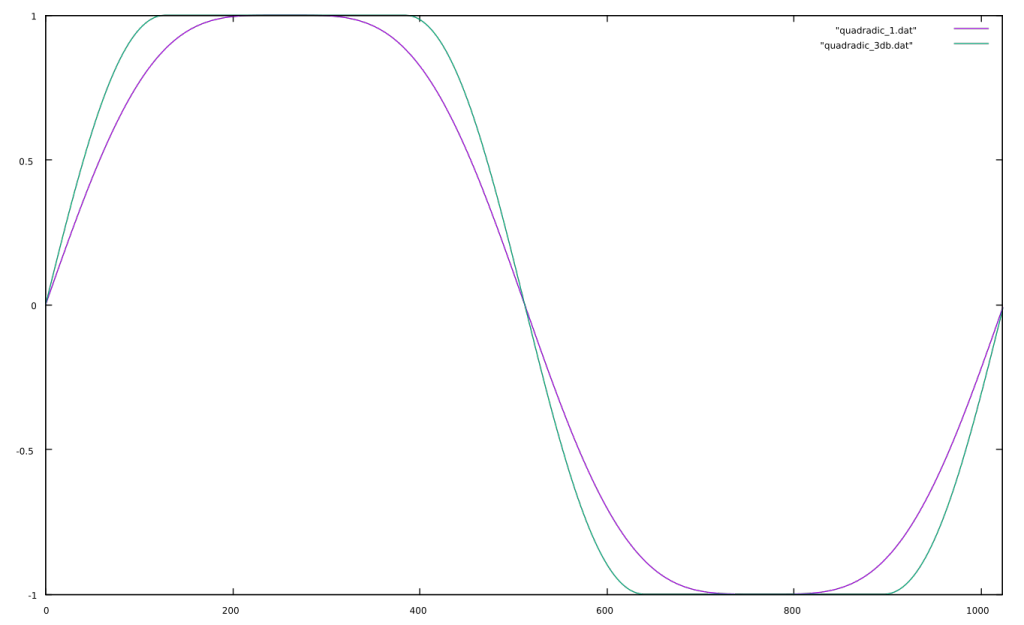
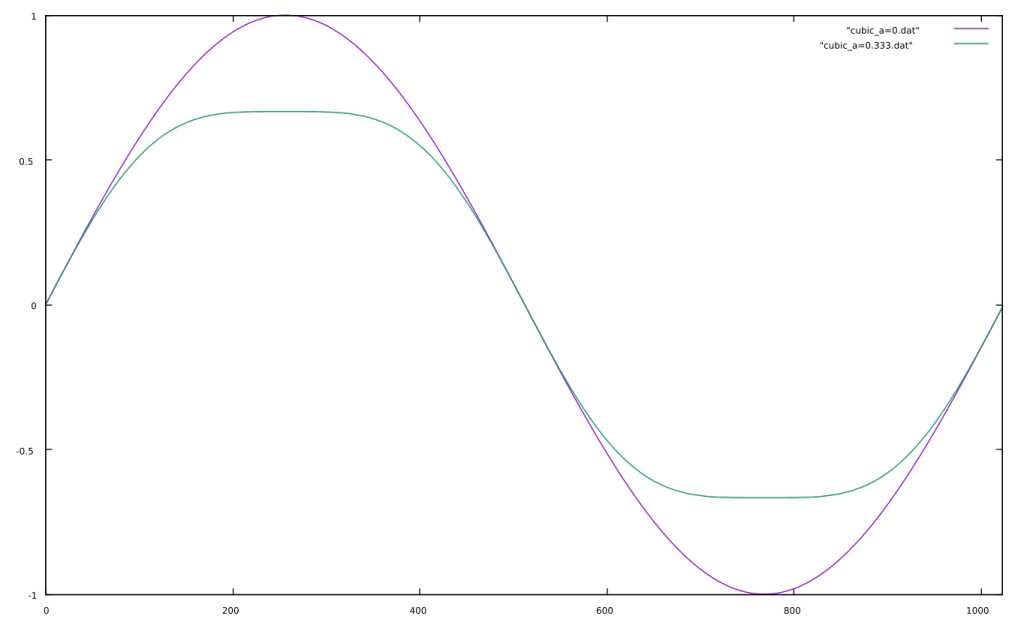
Wavefolding is a process which was originally used in the Buchla 259 complex waveform generator, a module from the Buchla 200 electronic music box and later in Serge synthesizers. It is a waveshaping function which “folds” back any input signal which exceeds a threshold. Usually there are positive and negative thresholds, so that both sides of the signal are folded. It is easiest to show this graphically.
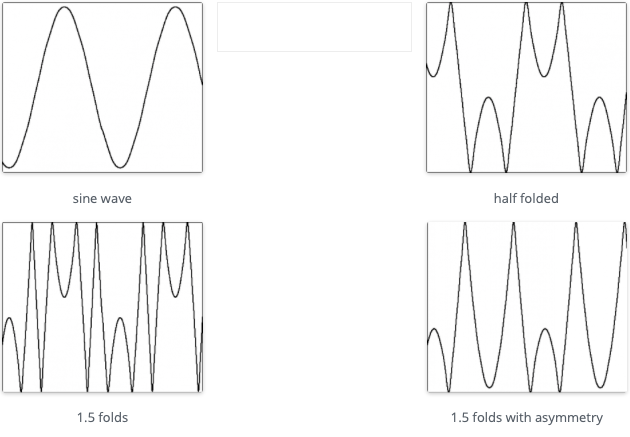
You can see how the sine wave is reversed on the top and bottom of the waveform and that this fold is reversed again in the 1.5x example when reaching the opposite threshold. The asymmetrical example is synthesized by adding a negative constant to the signal so that the negative threshold is reached before the positive one.
Wavefolding adds many new harmonics to any oscillator. This was a powerful technique on analog synthesizers as rich sounds could be created with just a handful of opamps and diodes.
Implementation
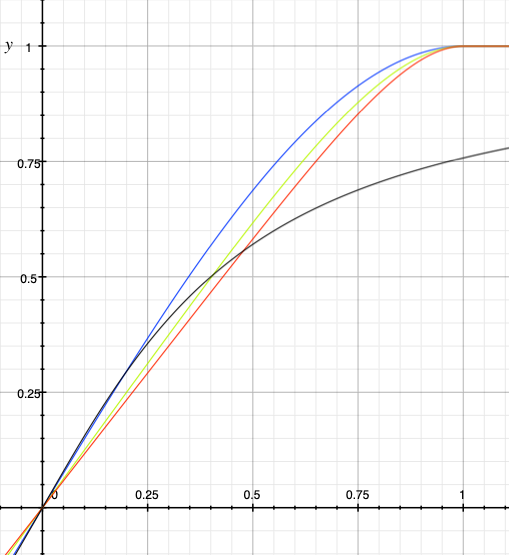
Wavefolding can be implemented by using a transfer function which reverses the signal at the positive and negative limits (-1 and 1), and again at -3, 3, -5, 5 and so on. The slope of this function should always be 1 or -1 (reversal). It is essentially a triangle wave. Here is a triangle wave approximated with it’s first 4 harmonics.
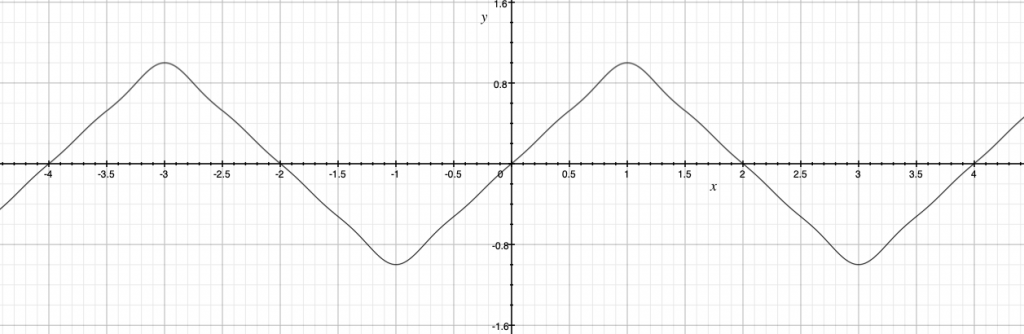
The incoming signal provides an index into the x axis, and the y axis is the output of the wavefolder. This can be implemented with a single cycle wavetable and a wrap function, or we can compute this directly from the modified triangle equation, sending the signal into x. As the signal is amplified beyond a gain of 1.0, wavefolding will start.
y_(x) = cos(.5\pi x) - \frac{1}{9} cos(1.5\pi x) + \frac{1}{25} cos(2.5\pi x) - \frac{1}{49} cos(3.5\pi x)Here is some example C code which uses the direct synthesis method.
WaveFolder(float *input, float *output, long samples, float gain, float offset)
{
int sample;
float pi = 3.141592653589793;
// iterate through the samples in the block
for(sample = 0; sample<samples; sample++)
{
// scale the input signal by gain and add offset
ingain = (gain * *(input+sample)) + offset;
*(output+sample) = cos(0.5 * pi * ingain)
- 1.0/9.0 * cos(1.5 * pi * ingain)
+ 1.0/25.0 * cos(2.5 * pi * ingain)
- 1.0/49.0 * cos(3.5 * pi * ingain);
}
}