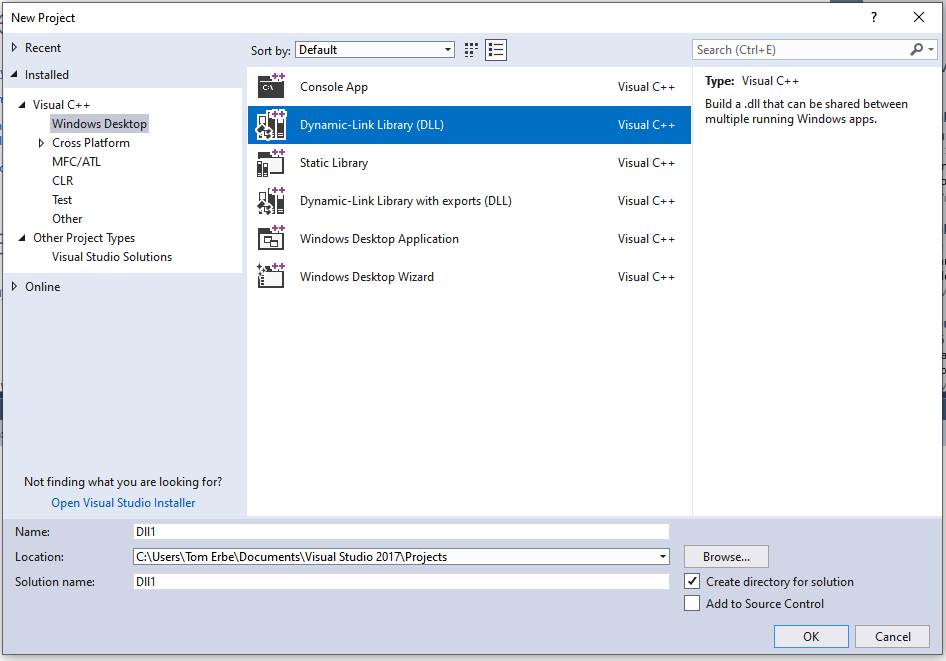
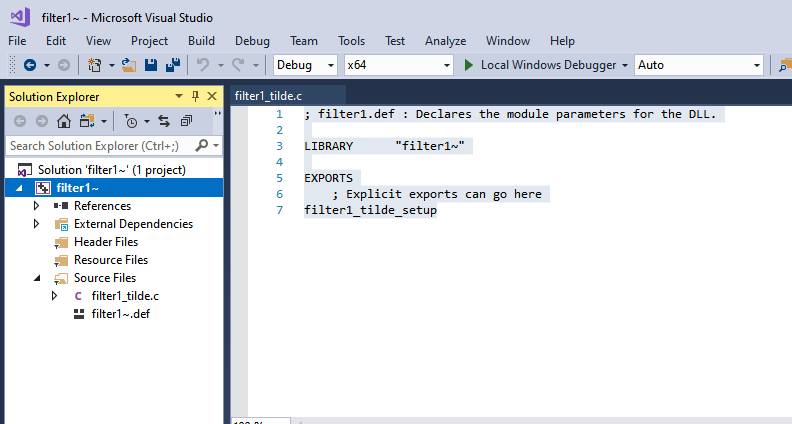
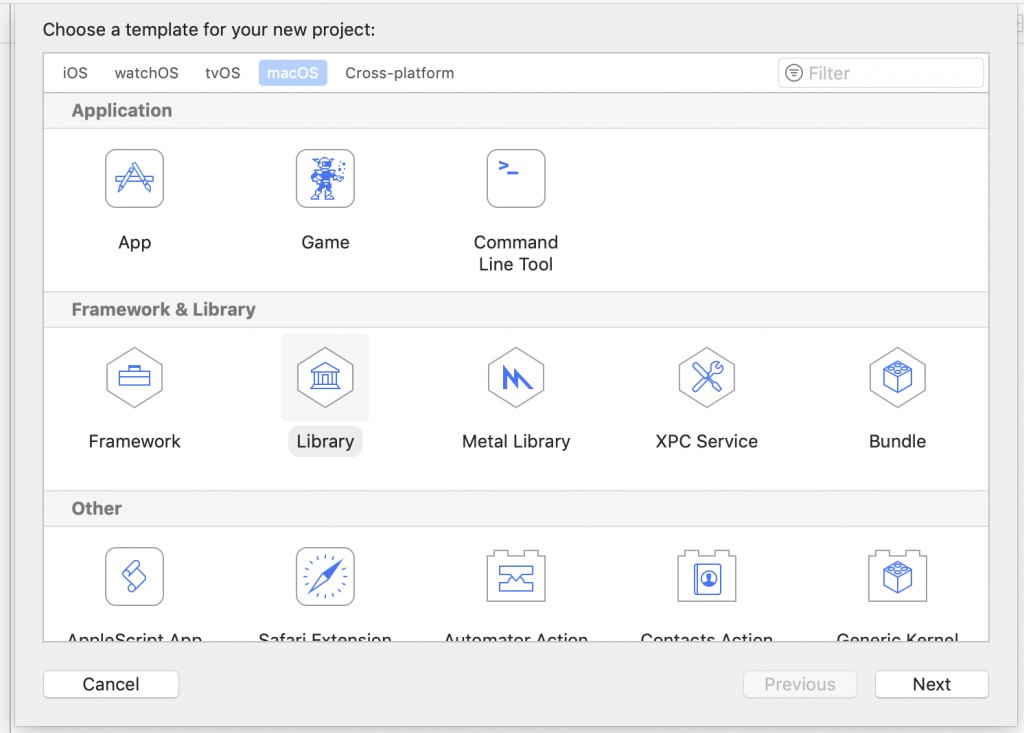
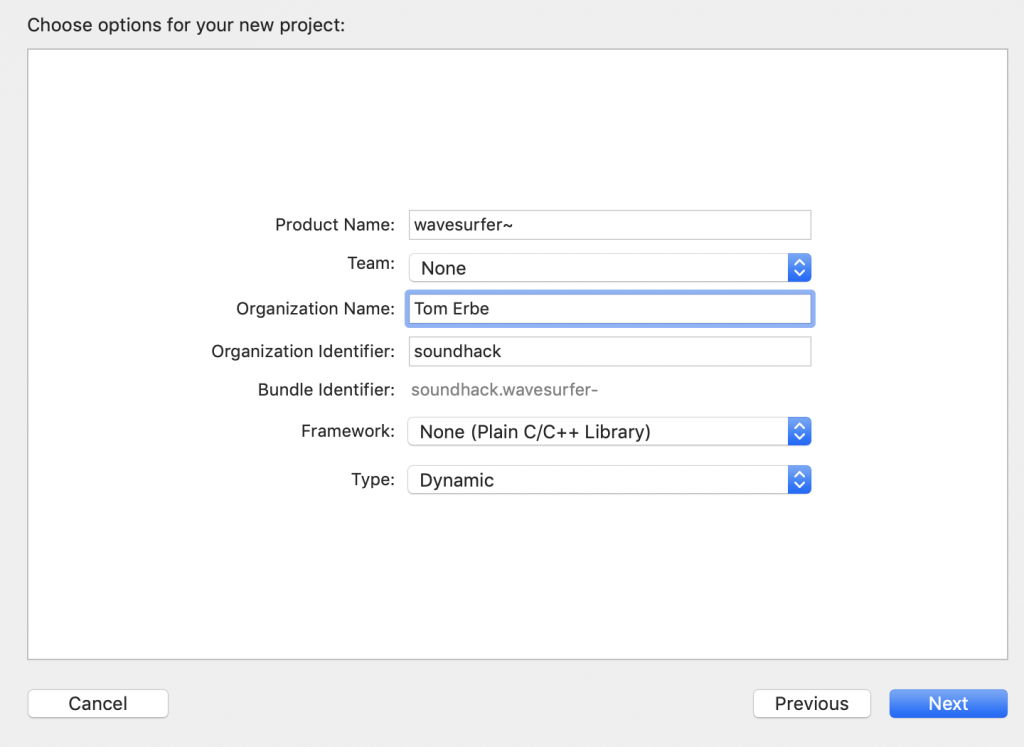
Create a new project (New>Project… from file menu)
Select Windows Destop in the template dialog under Visual C++, and Dynamic-Link Library in the center panel.
3. Enter the “Name:” in the lower panel. Click “OK”.
4. Click on your project name (right under the solution) and control click to bring up the project menu. Select properties. Change the following in the properties page.
C/C++ General
Additional Include Directories C:\Program Files\pd\src;%(AdditionalIncludeDirectories)
SDL checks No (/sdl-)
C/C++ Preprocessor
Preprocessor Definitions PD;NT;%(PreprocessorDefinitions)
C/C++ Precompiled Header
Precompiled Header Not Using Precompiled Header
Linker Input
Additional Dependencies oldnames.lib;kernel32.lib;C:\Program Files\pd\bin\pd.lib;%(AdditionalDependencies)
Module Definition File .\externalname.def
5. Add or create your external source code file (externalname.c). You might want to start with a known working file (obj1.c or dspobj.c) to start. Remove the Source Files dllmain.cpp and pch.cpp. Remove the Header Files framework.h and pch.h. A definition file will need to be created for the external to designate the setup function, this is pictured below.
6. Add the line “#define PD_LONGINTTYPE long long” above “#include “m_pd.h” if you are compiling for 64 bit.
7. You should now be able to build your external. Go to the build menu and select Build externalname.
8. To debug your external, create a .pd file in the folder that your external resides. Assuming you started Pure Data to create this file, your next step is to connect the debugger.
9. Go to the Debug menu and select Attach to Process. Do not attach to Pd.com, instead select pd.exe. This is the part of Pd that actually loads and runs your external.
10. Now you can enter break points in the .c file. Visual Studio will stop execution at these points so that you can inspect variables and check whether things are working properly.
11. Add your external to the .pd file you created in step 8. If all goes well, Xcode will jump to the foreground when it stops at the break point. Now you can look at variable and step through your code one line at a time.
5. Add or create your external source code file (externalname.c). You might want to start with a known working file (obj1.c or dspobj.c) to start.
6. You should now be able to build your external. Go to the product menu and select Build.
7. To debug your external, create a .pd file in the folder that your external resides. Assuming you started Pure Data to create this file, your next step is to connect the debugger.
8. Go to the Debug menu and select Attach to Process. Do not attach to Pd, instead, scroll further down to the “System” section and select pd. This is the part of Pd that actually loads and runs your external.
9. Now you can enter break points in the .c file. Xcode will stop execution at these points so that you can inspect variables and check whether things are working properly.
10. Add your external to the .pd file you created in step 7. If all goes well, Xcode will jump to the foreground when it stops at the break point. Now you can look at variable and step through your code one line at a time.
JUCE is an application framework in C++ for applications, apps and plugins; and can be used with many operating systems including macOS, Windows, Linux, iOS and Android. It is oriented around programming for audio, and has a large number of classes for audio, MIDI and video management as well as decent GUI and graphics support. The advantage of programming in JUCE is that you can support multiple OSs easily, and a large change in any of the OSs (such as the move of macOS to ARM) will usually not affect your programming.
Documentation
This webpage will only scratch the surface of JUCE plugin programming. To go further, you will need to do some research. Here are some resources you will use:
The JUCE Class Index – up to date documentation of every class in JUCE. Looking over this list is a good way to get familiar with everything in the framework
JUCE Tutorials – tutorials to help you get started on most uses of JUCE. These are simple and straightforward, so very good for beginning programmers.
The JUCE examples folder – This folder is contained in the JUCE distribution. It contains examples of many of the classes in JUCE. The project DemoRunner will build an application from this example code so that you can see the classes running in an application.
JUCE Forum – This is a good place to find answers when you get stuck. Usually there is someone else who asked your question already, so make sure to search before asking.
Getting Started with JUCE – This book is a good introduction to JUCE, but it is focussed on the basics of building an application, and it barely touches on audio or plugins.
A simple plugin
This example will be an autopan, an audio processor that uses a slow oscillator to cyclically pan from left to right to left and so-on. To create this plugin, several elements are needed:
a processing method – the method that performs the math to take an input sound and pan it, and the math that is needed to change the pan location automatically.
state variables – the variables which keep the current state of the process, in this case the current pan position and the phase of the panning oscillator.
parameter variables – the variables which represent the user controls on this plugin.
an editor – the window and user interface elements (sliders, knobs, buttons and text input) needed to change the parameter’s values, as well as provide a visual indication of those same values and other parts of the audio process (vu meter, waveform display, etc.).
To start plugin development, first open the ProJucer. This will create a code skeleton that will be fleshed out later. Select “New Project…” and click on “Audio Plug-In“. In the window that appears, type the plugin name (“Autopan”) and select your OS under “Target Platforms“, click “Create” and the project window will open.
The C++ source files are in the left column under File Exporter, the other sections in the left column are Modules – C++ code from JUCE, and Exporters – the target OS and development system. There is also a small gear icon on the upper right top of the left column. This is where general plugin settings are entered. Scroll down to plugin formats and select AU (macOS only) and standalone. The Steinberg VST SDK is needed to develop VST and VST3 plugins, we will do this later in class.
You can edit your software and compile it in the Projucer, but in class we will look at using Xcode or Visual Studio to edit and compile. To open one of these, click the button with the Xcode or Visual Studio icon on the upper right part of the Projucer window. The skeleton code will create a working plugin, one that simply passes audio without changing it. After you select “Build” in the compiler, the compiler will create a standalone application and an audio unit (on macOS). The finished files can be seen in the Products area in the compiler, and if all goes well, will look like this when you start it.
Editing the Processing Method
The method processBlock is in the file PluginProcessor. It receives two parameters, a pointer to an AudioBuffer and a pointer to a MidiBuffer which contain the samples and MIDI messages collected during the last audio block. We need to change the code at the bottom of this method. The default reads as follows:
for (int channel = 0; channel < totalNumInputChannels; ++channel)
{
auto* channelData = buffer.getWritePointer (channel);
// ..do something to the data...
}
This for loop is organized to apply the same processing to each channel separately. For panning, we need separate processing for each channel, so we will remove the for loop. Instead we will derive separate pointers for left and right input and output samples arrays from the AudioBuffer. In addition, we will add a for loop for sample-by-sample processing.
auto leftInSamples = buffer.getReadPointer(0);
auto rightInSamples = buffer.getReadPointer(1);
auto leftOutSamples = buffer.getWritePointer(0);
auto rightOutSamples = buffer.getWritePointer(1);
for(int sample = 0; sample < buffer.getNumSamples(); sample++)
{
// make it a mono input
double monoIn = (*(leftInSamples+sample) + *(rightInSamples+sample)) * 0.5;
// compute phase for 0.1Hz
phase = phase + 0.1/getSampleRate();
// if phase goes over 1.0, subtract 1.0
if(phase >= 1.0)phase -= 1.0;
// create a sine wave from the phase
double sineMod = sin(2.0 * 3.141592653589793 * phase);
// scale and offset so it goes from 0 to 1, rathen than -1 to 1
sineMod = (sineMod + 1.0) * 0.5;
// use the sine wave to modulate the volume of the
// left and right output
*(leftOutSamples+sample) = sineMod * monoIn;
*(rightOutSamples+sample) = (1.0 - sineMod) * monoIn;
}
}
The variable phase has not been declared, so will cause an error if you try to compile this code. It is a state variable, that is, it is a value represents the changing state of the process and needs to be preserved after the processBlock method. To do this, we will declare it as a member of the AutopanAudioProcessor. Edit the file PluginProcessor.h and add the line
double phase;
private:
above private: . Also, in the class constructor AutopanAudioProcessor::AutopanAudioProcessor() set the initial phase to 0.0.
#endif
{
phase = 0.0;
}
Once this is compiled, you can test it in any Audio Unit host. You should clearly hear the music moving left to right and back again.
Parameters and GUI Controls
Internal parameters and GUI controls ideally should be implemented at the same time, as they are dependent on each other. Not only do the GUI controls set the internal parameter, but automation and the host app will also set it. In this case the GUI needs to respond to the change of parameter and display the same value. As this would mean moving a slider or other control to match the parameter, it is important that the slider doesn’t send a parameter change back to the internal process. To prevent this loop and to remain compatible with automation logic from various DAWs, a number of connected classes are used.
Slider: the GUI control
SliderAttachment: this connects the GUI to the parameter
AudioProcessorValueTreeState: a container for organized parameters
We can start by adding a AudioProcessorValueTreeState to the AudioProcessor. Edit PluginProcessor.h and add it in the public: section of the class definition (we will later access this object from the AudioProcessorEditor).
Now that we have the parameter container, we can add a parameter or more to parameters in the PluginProcessor constructor initializer list (look this up in your C++ book). First, parameter is initialized, then a bracketed list of parameters are created and added. Within the constructor, the pointers to data are copied to pointers in the AutopanAudioProcessor class so that they can be referred to later (and won’t go out of scope). Once we compile this, we should see and be able to set the parameters in Ableton Live.
AutopanAudioProcessor::AutopanAudioProcessor()
: parameters (*this, nullptr, juce::Identifier ("APVTSAutopan"),
{
std::make_unique<juce::AudioParameterFloat> ("lfofreq", // parameterID
"Frequency", // parameter name
0.1f, // minimum value
10.0f, // maximum value
1.0f), // default value
std::make_unique<juce::AudioParameterFloat> ("lfodepth", // parameterID
"Depth", // parameter name
0.0f, // minimum value
1.0f, // maximum value
0.5f), // default value
})
{
// pointers are copied to items declared in object so they don't go out of scope
depthParm = parameters.getRawParameterValue ("lfodepth");
freqParm = parameters.getRawParameterValue ("lfofreq");
}
// in the class definition
juce::AudioProcessorValueTreeState parameters;
private:
std::atomic<float>* depthParm = nullptr;
std::atomic<float>* freqParm = nullptr;
//==============================================================================
// and finally, in processBlock
auto rightOutSamples = buffer.getWritePointer(1);
for(int sample = 0; sample < buffer.getNumSamples(); sample++)
{
// make it a mono inputdouble monoIn = (*(leftInSamples+sample) + *(rightInSamples+sample)) * 0.5;
// compute phase for 0.1Hz
phase = phase + *freqParm/getSampleRate();
// if phase goes over 1.0, subtract 1.0if(phase >= 1.0)phase -= 1.0;
// create a sine wave from the phasedouble sineMod = sin(2.0 * 3.141592653589793 * phase) * *depthParm;
Adding Sliders to the AudioProcessorEditor class
First we need to declare both Slider and SliderAttachment objects in the AudioProcessorEditor class. The SliderAttachment connects the Slider control to the AudioProcessorValueTreeState and takes care of automation and all other parameter changes. We need one of each object for each parameter, and we can declare them in the private area of PluginEditor.h.
We will now initialize the SliderAttachment objects in the AudioProcessorEditor constructor initializer list. Make sure to enter the parameterID that is used for each respective parameter.
Finally, we can initialize the Slider objects in the AudioProcessorEditor constructor. There are many parameters that can be set to customize the look of the Slider. Note that the range and default values are copied from the AudioProcessorValueTreeState, so they do not need to be set. The method addAndMakeVisible will connect the Slider to the AudioProcessorEditor as a child component, and will make it visible.
AutopanAudioProcessorEditor::AutopanAudioProcessorEditor (AutopanAudioProcessor& p)
: AudioProcessorEditor (&p),
lfoDepthSA(p.parameters, "lfodepth", lfoDepthSlider),
lfoFreqSA(p.parameters, "lfofreq", lfoFreqSlider),
audioProcessor (p)
{
lfoFreqSlider.setName("LFO Frequency");
lfoFreqSlider.setBounds (10, 10, 300, 20);
addAndMakeVisible(&lfoFreqSlider);
lfoDepthSlider.setName("LFO Depth");
lfoDepthSlider.setBounds (10, 40, 300, 20);
addAndMakeVisible(&lfoDepthSlider);
// Make sure that before the constructor has finished, you've set the
// editor's size to whatever you need it to be.
setSize (400, 300);
}
At this point you may want to customize the look of the plugin background by adding graphics programming to the paint method. This method receives a Graphics object, and it is worth spending some time learning the methods in this object.
Customization of the Slider and TextButton objects can be achieved by creating your own LookAndFeel class. The methods of the LookAndFeel class will override the paint methods of all of the GUI objects in juce.
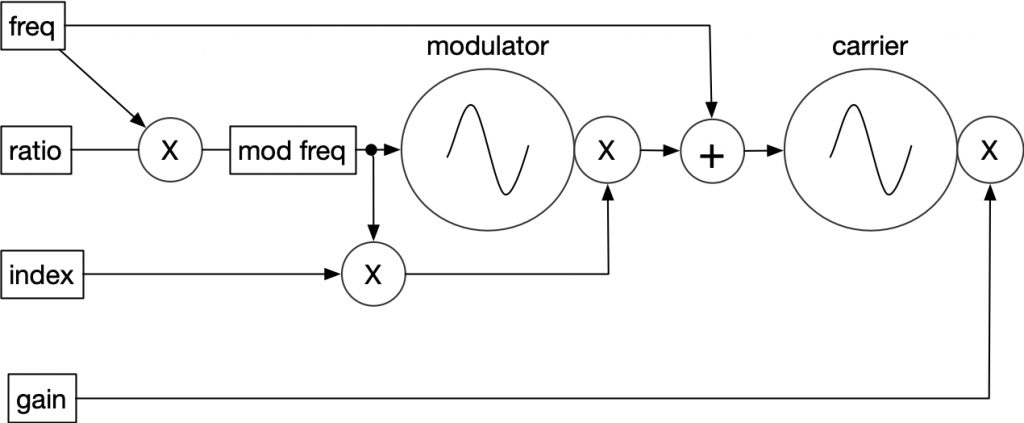
Frequency Modulation is a synthesis technique that all should be familiar with. FM synthesis was invented by John Chowning in 1968, and subsequently the most commercially popular digital synthesis method. It involves at least 2 operators (sine oscillator with amplifier), in which one is the modulator and the other is the carrier (the operator being modulated, as well as the one that is heard).
The theory of FM synthesis can be found in Chowning’s article “The Synthesis of Complex Audio Spectra by Means of Frequency Modulation”. Breifly, frequency modulation acts somewhat like amplitude modulation in that upper and lower sidebands are created around the carrier frequency. These sidebands are separated from the frequency of the carrier by the frequency of the modulator, so that they appear at f_{car} + f_{mod} and f_{car} - f_{mod}. What separates FM from AM is that additional sidebands appear at multiples of the modulator frequency, and increased depth of modulation increases the strength of higher sidebands. Also when f_{car} - n*f_{mod} drops below 0Hz, it reflects around 0Hz with a phase inversion. As with AM, a simple harmonic relation between the carrier and modulator will create a more consonant sound Finally, multiple carriers and modulators can be used to specify a spectrum in more detail, and modulation feedback can be used to create noise and chaotic oscillation..
simple two operator frequency modulation
Implementation
One of the attractive aspects of two operator FM synthesis is that this very straightforward and seemingly simple structure can intuitively create many timbres. The index parameter acts very much like a brightness control, a ratio of 1 will synthesize all harmonics, a ratio of 2 will create odd harmonics, and higher ratios further separate the overtones. The only limit to index and ratio is the Nyquist frequency.
In C, two table lookup oscillators are used. In practice, interpolation would be used in these oscillators to reduce quantization noise.
// the samplerate in Hz
float sampleRate = 44100;
// initial phase
float phaseCar = 0.0;
float phaseMod = 0.0;
long tableSize = 8192;
long tableMask = 8191;
float sineTab[8192];
void InitTables(void)
{
// create sineTab from sin()
for(i = 0; i < tableSize; i++)
{
sineTab[i] = sin((6.283185307179586 * i)/tableSize);
}
}
void TwoOpFM(float *input, float *output, float frequency, float ratio, float index, float gain, long samples)
{
long sample;
float phaseIncCar, phaseIncMod;
float carrier, modulator;
// calculate for each sample in a block
for(sample = 0; sample < samples; sample++)
{
// get the phase increment for this sample
// frequency of modulator is frequency of carrier * ratio
phaseIncMod = (frequency * ratio)/sampleRate;
// calculate the waveforms
modulator = sineTab[(long)(phaseMod * tableSize)];
phaseIncCar = (frequency + (modulator * frequency * ratio * index))/sampleRate;
carrier = sineTab[(long)(phaseCar * tableSize)];
*(output+sample) = carrier * gain;
// increment the phases
phaseMod = phaseMod + phaseModInc;
phaseCar = phaseCar + phaseIncCar;
if(phaseMod >= 1.0)
phaseMod = phaseMod - 1.0;
// phaseCar can get large fast and can go negative
// must be kept between 0 and 1
while(phaseCar >= 1.0)
phaseCar = phaseCar - 1.0;
while(phaseCar < 0.0)
phaseCar = phaseCar + 1.0;
}
}
2 op FM with random index and ratio
Multiple Carriers, Feedback FM and further
One could easily add more to this simple network. One of the common additions is that of a second carrier with it’s own index of modulation. This can be used to simulate formants, or increase upper harmonics without increasing middle harmonics.
Feedback is often used in small amounts to create a bit of noise for the attack of the note. This can be done by adding a modulation path from the carrier to the modulator. There will be an additional sample delay in this feedback, but this technique can create a wide variety of noise depending on the index and frequency.
Finally, there are many, many papers on synthesis with FM, as well as commercial instruments that have some very expressive FM patches. It is well worth it to study these patches and techniques.
Single sideband amplitude modulation shifts the frequency either upward or downward, but not both directions (as in AM). This technique is based on the trigonometric identity we used earlier. Shifting a cosine up simply takes half of a complex multiplication.
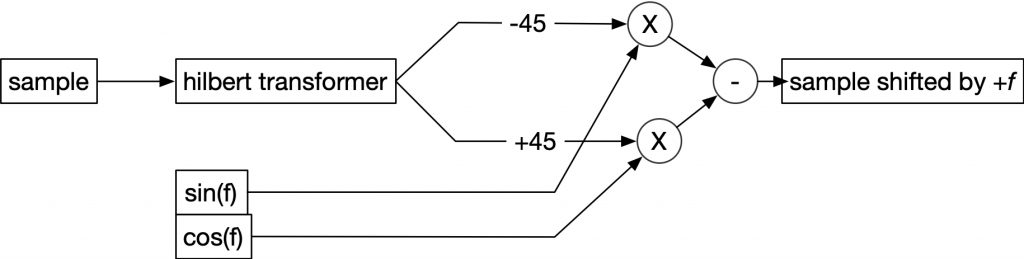
Alpha and beta represent the frequencies of the signal sources. Each of these frequencies requires a cosine and sine oscillator pair. By subtracting the sin() product from the cos() product, a frequency shifted (alpha+beta) oscillator is synthesized. If the products are summed, a downward (alpha-beta) oscillator is synthesized. As cosine and sine are separated by 90 degrees, it is simple enough to create a cosine/sine pair from a sinusoidal oscillator – simply add 90 degrees to the phase of the oscillator to create the second of the pair.
However, single sideband AM is more often used to frequency shift sampled signals. To do this, it is useful to consider the sample as a sum of multiple sinusoidal oscillators. To perform SSB AM, the original sample as well as a 90 degree phase shifted sample is needed. Phase shifting all of the sinusoidal components of a sample 90 degrees can be done with a type of allpass filter called a Hilbert transformer. If well designed, a Hilbert transformer will shift most frequencies 90 degrees, and will maintain this phase shift until close to 0Hz and the Nyquist frequency. Many implementations have two outputs which are 90 degrees apart, but not in phase with the original sample.
There are several open source Hilbert transformers in popular audio software. One is in Miller Puckette’s Pure Data, and is implemented as 2 pairs of biquad filters (a biquad filter was used in the earlier second order allpass filter example). It is based on a 4X synthesizer patch by Emmanuel Favreau. The other is in the Csound source code, designed by Sean Costello and based on data from Bernie Hutchins.
The difference equations for the Favreau Hilbert transformer are:
Amplitude Modulation (aka ring modulation) is one of the simplest synthesis techniques to implement, but one of the lesser used techniques. AM uses the multiplication of two signals to create new harmonics. The product will contain the sum and difference of all of the harmonics in the original waveforms. This comes from the combinations of the phase change in the original waveforms. If you take the difference of two trigonometric angle sum and difference identities you can see how the new frequencies are derived from the multiplied sines.
As the frequencies are being shifted with sum and difference, these new harmonics can easily lose any harmonic relation they had in the original signals. For example, if a waveform with related harmonics of 100Hz, 200Hz and 500Hz is modulated by a 96Hz sine, the new harmonics will be at 4Hz, 104Hz, 196Hz, 296Hz, 404Hz and 596Hz. There are no simple harmonic relations in the new tone.
96Hz sine * 100,200&500Hz sine“Walk This Way” break * sine sweep from 1k to 0Hz
Amplitude Modulation Techniques
AM can be configured in several ways to get more consonant results. The C code below will show how to achieve the following three methods.
By restricting the frequencies used in AM, a more useful result is obtained. If simple harmonic relations are maintained between the two source waveforms, harmonic relations will be maintained in the product.
The original waveforms can be reintroduced into the output by adding two parameters. This can be very useful if one of the sources isn’t sinusoidal. y(t) = \alpha*(sin(\omega_1 t)*sin(\omega_2 t) + \beta*sin(\omega_1 t) + \gamma*sin(\omega_2 t))
A simple harmonic tone generator can be created using feedback and self modulation.
Implementation
AM is usually implemented with a simple multiply and two source signals. Our first C example will create an AM oscillator with internal sqaure and sine wave oscillators. It will also implement gain parameters for the original waveforms.
// the samplerate in Hz
float sampleRate = 44100;
// initial phase
float phaseSin, phaseSqu = 0.0;
long tableSize = 8192;
long tableMask = 8191;
float squareTab[8192];
float sineTab[8192];
void InitTables(void)
{
// create sineTab from sin() and squareTab from 11 first harmonics of square wave
for(i = 0; i < tableSize; i++)
{
sineTab[i] = sin((6.283185307179586 * i)/tableSize);
squareTab[i] = sin((6.283185307179586 * i)/tableSize);
squareTab[i] += sin((6.283185307179586 * i * 3.0)/tableSize)/3.0;
squareTab[i] += sin((6.283185307179586 * i * 5.0)/tableSize)/5.0;
squareTab[i] += sin((6.283185307179586 * i * 7.0)/tableSize)/7.0;
squareTab[i] += sin((6.283185307179586 * i * 9.0)/tableSize)/9.0;
squareTab[i] += sin((6.283185307179586 * i * 11.0)/tableSize)/11.0;
squareTab[i] += sin((6.283185307179586 * i * 13.0)/tableSize)/13.0;
squareTab[i] += sin((6.283185307179586 * i * 15.0)/tableSize)/15.0;
squareTab[i] += sin((6.283185307179586 * i * 17.0)/tableSize)/17.0;
squareTab[i] += sin((6.283185307179586 * i * 19.0)/tableSize)/19.0;
squareTab[i] += sin((6.283185307179586 * i * 21.0)/tableSize)/21.0;
}
}
void RingOsc(float *input, float *output, float frequency, float ratio, float ringGain, float sineGain, float squareGain, long samples)
{
long sample;
float phaseIncSin, phaseIncSqu;
float sinSamp, squSamp;
// calculate for each sample in a block
for(sample = 0; sample < samples; sample++)
{
// get the phase increment for this sample
phaseIncSqu = frequency/sampleRate;
phaseIncSin = phaseIncSqu * ratio;
// calculate the waveforms
sinSamp = sineTab[(long)(phaseSin * tableSize)];
squSamp = squareTab[(long)(phaseSqu * tableSize)];
// mix the output from ring, sine and square
*(output+sample) = sinSamp * squSamp * ringGain + squSamp * squareGain
+ sinSamp * sineGain;
// increment the phases
phaseSin = phaseSin + phaseIncSin;
if(phaseSin >= 1.0)
phaseSin = phaseSin - 1.0;
phaseSqu = phaseSqu + phaseIncSqu;
if(phaseSqu >= 1.0)
phaseSqu = phaseSqu - 1.0;
}
}
square * sine ring oscillator with ratio of 3 and modulation of square and sine gain
As stated earlier, a simple harmonic oscillator can be made by using a single sinewave oscillator, AM and feedback. Feedback needs to be kept under 1.0 or the algorithm will become unstable. As the feedback gain increases, more and more harmonics will be added. A small offset needs to be added to the feedback to give the sound an initial gain. Not a very rich technique, but worth knowing….
// the samplerate in Hz
float sampleRate = 44100;
// initial phase
float phase = 0.0;
float fbSamp;
long tableSize = 8192;
long tableMask = 8191;
float sineTab[8192];
void InitTables(void)
{
// create sineTab from sin()
for(i = 0; i < tableSize; i++)
{
sineTab[i] = sin((6.283185307179586 * i)/tableSize);
}
}
void RingFBOsc(float *input, float *output, float frequency, float feedback, long samples)
{
long sample;
float phaseInc;
float sinSamp, squSamp;
if(feedback > .95) feedback = .95;
// calculate for each sample in a block
for(sample = 0; sample < samples; sample++)
{
// get the phase increment for this sample
phaseInc = frequency/sampleRate;
// calculate the waveforms
sinSamp = sineTab[(long)(phase * tableSize)];
// ring modulate with last output * feedback
fbSamp = sinSamp * ((fbSamp * feedback) + 0.1)
*(output+sample) = fbSamp;
// increment the phase
phase = phase + phaseInc;
if(phase >= 1.0)
phase = phase - 1.0;
}
}
random bass line with single oscillator feedback AM modulation
Many characteristic effects can be created by configuring the delay in the right way. I will describe how to get some of these effects.
Comb Filtering
For comb filtering, the time needs to be very short, from about 40ms to .1ms. An exponential time control will help in tuning specific pitches. To get the filter to ring, the feedback should be very high, about 90% and above (even above 100%). There should be less compression (or no compression) in the feedback loop. Saturation in the feedback loop can make this effect really stand out.
Flanging
Flanging can be achieved by starting with the comb filter settings above. Modulate the time slowly (1/10th to 2Hz) with a triangle wave from the delay’s minimum time to 10 – 40ms. A low pass filter in the feedback loop can change the timbre of the flange effect.
Multitap Echo
A “tap” is a secondary output of the same delay with a different time. Implementation is fairly simple – add multiple reads of the delay buffer, each with a different delay time. These multiple outputs can create a rhythmic pattern, and each delay output could have a separate gain control. Mix all of the outputs, and be careful not to distort as the taps are summed.
Chorusing
This can be done with one or many taps. The delay times are modulated without much depth around 30ms (so from 29 to 31ms is typical). Modulation is typically done with a sine wave at a low frequency (like the flanger). If multiple taps are used, each one should be modulated by a different phase sine wave, and if possible, output to different spatial locations. Feedback is typically low when chorusing, unless a “seasick” pitch warble is desired.
Loop/Freeze
Delay looping is not the same as a full feature looper, but can be used for some loop applications. Simply set the feedback to 100% (1.0) and the input gain to 0.0, and the sound will be held and repeated.
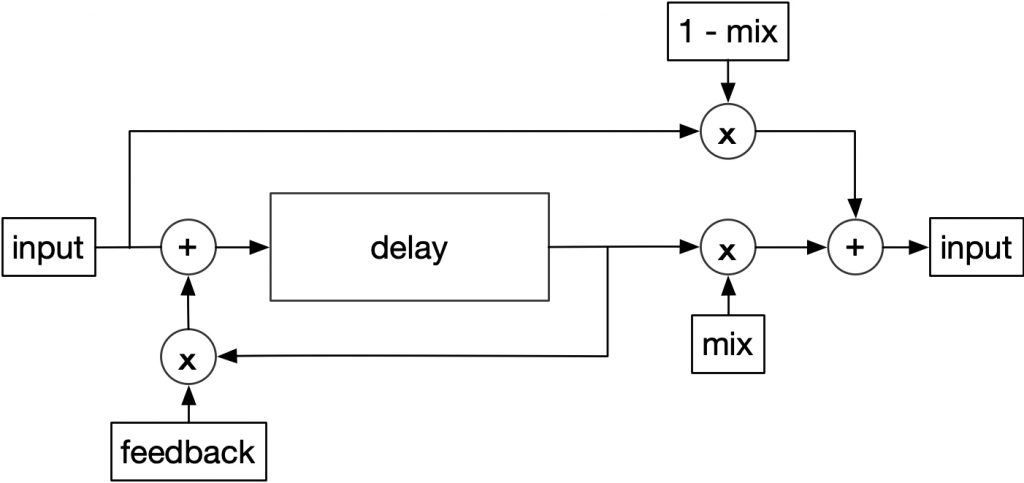
Adding feedback to a delay is fairly straightforward: output = input + delayouput * feedback , where feedback ranges from 0.0 to 1.0 (and often over 1.0). Adding a feedback path is what creates multiple echoes, with a naturally exponential decay. A typical implementation is to send the delay output to an input/output mix, and apply feedback gain before the delay output is mixed with the input. In this configuration, mix determines the balance of the delay and the input, and feedback controls the decay of each echo.
typical delay configuration with feedback and wet./dry mix.
Note that delay output * feedback + input, has a gain of 1.0 + feedback. This will drive the delay into clipping when there are input signals over 0.5. There are a number of options to control the gain (keep it at 1.0): gain reduction based on feedback, compression, saturation, or a combination of the these. Simple gain reduction would place a gain element before the delay input so that the overall gain is reduced as the feedback increases.
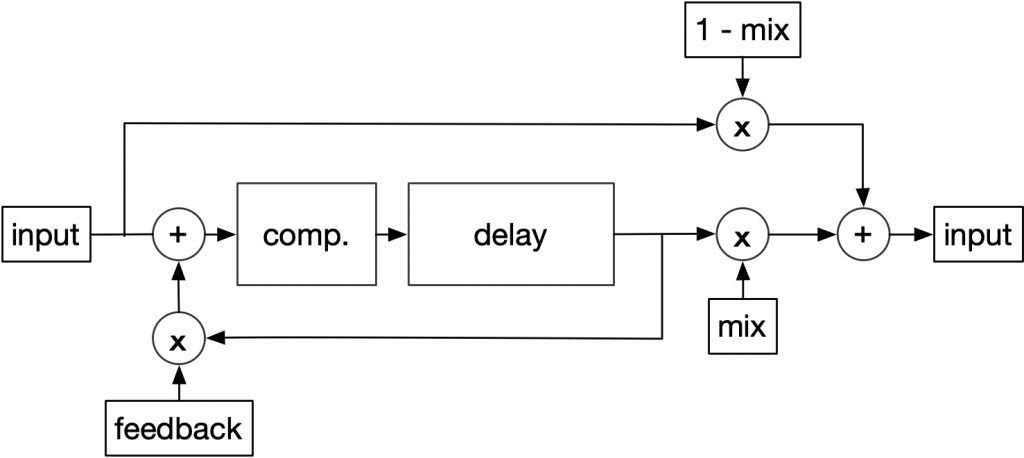
This is the cleanest sounding approach, but is sometimes felt to be too “clinical”. A combination of compressor and saturator is more typically used.
compression after feedback/input mix to keep signal under 1.0
This compressor will measure the level before the delay input and apply a gain lower than 1.0 to control the signal. This gain can be applied before the delay input or to the feedback signal.
Finally, when implementing any feedback network, there is a danger of DC offset building up. If using feedback higher than 1.0 this is especially likely. A DC blocking filter (a high pass at a subsonic frequency) in the feedback path should be tuned to remove any DC offset without negatively affecting low frequencies.
Implementation
The addition of feedback and wet/dry mix to a delay is fairly simple. Saturation can be added before the delay input. A compressor can be implemented as it was in the earlier section, but in the case where the threshold is fixed and the amount of gain reduction needed is known, a gain table can be kept in memory, or a polynomial can be used to calculate gain. This polynomial can be created by curve fitting through the known gain reduction points (polyfit in MatLab can do this, as can several online solvers).
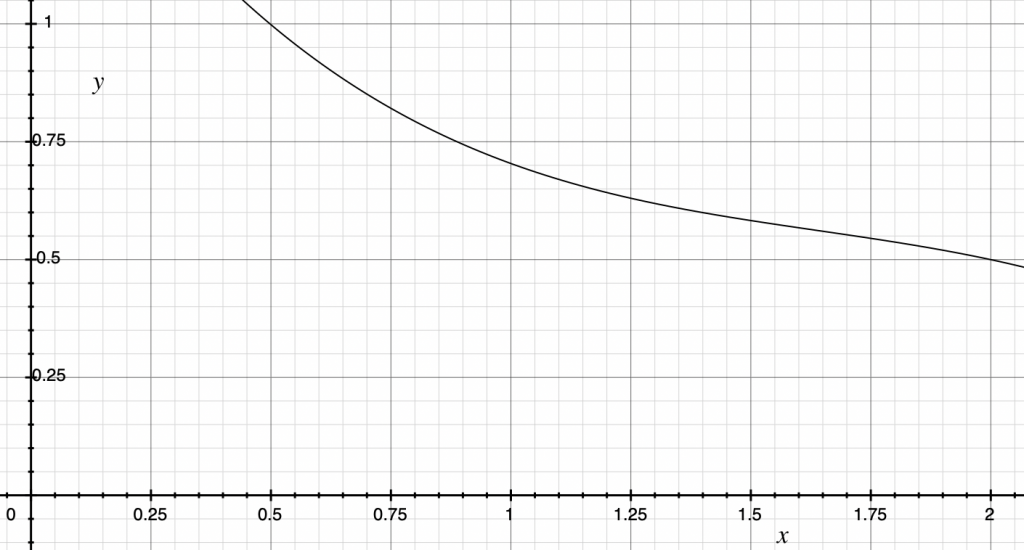
y=1.60154 – 1.60573x + 0.88839x^2 – 0.18048x^3 (gain of 1 at .5, gain of .5 at 2)
// this code uses the earlier linear interpolation method
long writePointer, delayMask;
float *delayBuffer;
float delayTime;
float sampleRate = 48000.0f;
float peak;
void DelayInit(long delaySize)
{
delayBuffer = new float[delaySize];
delayMask = delaySize - 1;
writePointer = 0;
delayTime = 0.0f;
peak = 0.0f;
}
void DelayTerm(void)
{
delete[] delayBuffer;
}
void Delay(float *input, float *output, long samples, float time, float feedback, float mix)
{
float readPointer;
long readPointerLong, i;
float fraction;
float x0, x1, out, in, rect;
delayTimeInc;
// find increment to smooth out delayTime
delayTimeInc = (time - delayTime)/samples;
for(i = 0; i < samples; i++)
{
in = *(input+i);
// linear interpolated read
readPointer = writePointer + (delayTime*sampleRate);
readPointerLong = (long)readPointer;
fraction = readPointer - readPointerLong;
// both points need to be masked to keep them within the delay buffer
x0 = *(delayBuffer + (readPointerLong & bufferMask));
x1 = *(delayBuffer + ((readPointerLong + 1) & bufferMask));
out = x1 + (x2 - x1) * fraction;
// wet/dry mix
*(output+i) = out * mix + in * (1.0 - mix);
// add feedback output to input
rect = in = in + feedback * out;
// rectify input for simple peak detection
if(rect < 0.0) rect = rect * -1.0;
// if the signal is over the peak, use one pole filter for quick fade of peak to signal
if(peak < rect)
peak = peak + (rect - peak) * 0.9f;
// otherwise fade peak down slowly
else
peak *= 0.9999f;
// polynomial compression
// if feedback goes up to 1.0, a maximum peak of 2.0 is possible
if(peak > 2.0)
peak = 2.0;
else if(peak < 0.5f)
peak = 0.5f;
in = in * (1.601539 - (1.605725 * peak)
+ (0.8883899 * peak * peak)
- (0.180484 * peak * peak * peak));
// now it can go in the delay
*(delaybuffer + writePointer) = in;
// move the write pointer and wrap it by masking
writePointer--;
writePointer &= delayMask;
// smooth the delayTime with the increment
delayTime = delayTime + delayTimeInc;
}
delayTime = time;
}
The delay code in the previous posting quantizes the delay value to the sample. This can cause problems when modulating the delay time, as many modulated delay effects (doppler shift, comb filtering, chorusing, flanging) depend on sub-sample time accuracy. It is also necessary to smooth the time control to decrease parameter change noise (aka “zipper noise”). When adjusting the delay time with a mouse (in a plugin or app), the time parameter will only be updated once per sample block. This sporadic parameter change needs to be smoothed through interpolation or other filtering techniques. Finally, if your delay time is being controlled by an analog control, there is often noise or jitter in this control. This also needs to be smoothed. In this section a few of these techniques will be presented.
Fractional Delay
A fractional delay estimates possible values between actual samples, by using a interpolation or curve fitting technique.
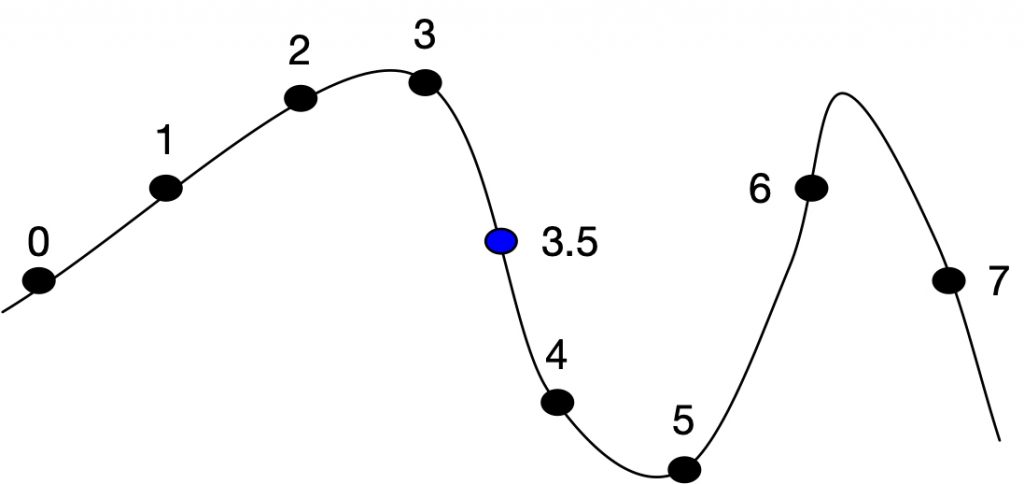
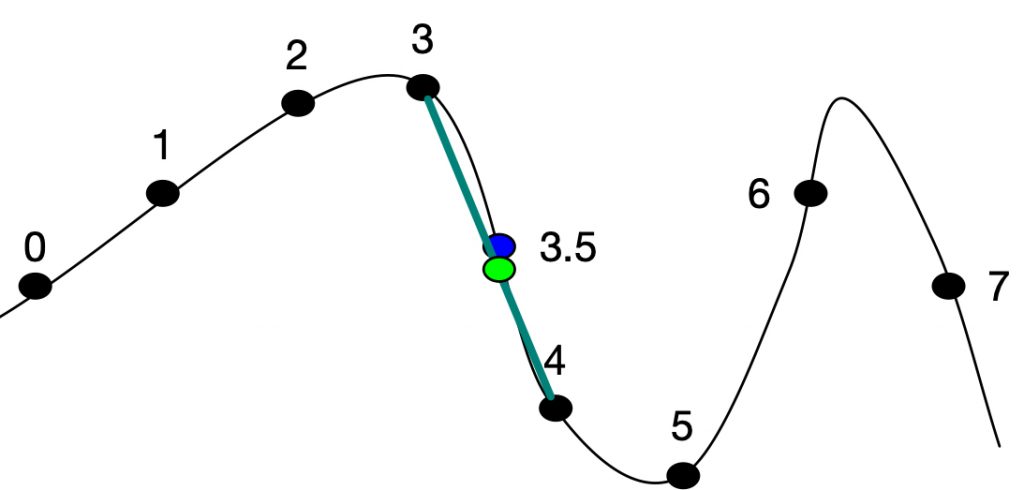
possible curve for 7 samples
If the sample rate is 48k, and a delayed sample at time .0729ms is needed, the sample at location 48 * 0.0729 = 3.5 is needed. Of course, there is no sample 3.5, but an estimate can be made. There are several common techniques to finding this value (these are the same techniques used in a table lookup oscillator):
truncation
rounding
linear interpolation
hermite interpolation
other interpolation functions
Truncation is the simplest of these techniques. Simply truncate any number right of the decimal point and 3.5 becomes 3. This is the fastest, and worst sounding method. Rounding involves finding the closest integer. It is the same as adding 0.5 to the floating point sample number and then truncating – 3.5 becomes 4. It sounds as bad as truncation but involves more computation. Linear interpolation is a much better estimate. This involves calculating the value between 3 and 4 by a simple crossfade.
The value given by linear interpolation will have error, but is much better than the value given by truncation.
Even more accurate are curve fitting functions like the 4 point hermite cubic interpolator which is discussed in great detail in the oscillator section of this website. It uses the 4 points around 3.5 (2, 3, 4, 5) to estimate the value at 3.5 giving more weight to points 3 and 4. There are many interpolators, using more or less points, and with varying accuracy and CPU performance. A good discussion of these is in this paper by Olli Neimitalo.
Implementation
To implement linear interpolation, the sample points around the fractional point are needed. The the first sample number (3 in the example) is subtracted from the desired sample number (3.5) to get the fraction (0.5). We can use this fraction to estimate the value at 3.5: y = x_{3} * (1 - frac) + x_{4} * frac or y = x_{3} + (x_{4} - x_{3}) * frac .
// The sample reading code is modified for linear interpolation
float readPointer;
long readPointerLong;
float fraction;
float x0, x1;
readPointer = writePointer + (delayTime*sampleRate);
readPointerLong = (long)readPointer;
fraction = readPointer - readPointerLong;
// both points need to be masked to keep them within the delay buffer
x0 = *(delayBuffer + (readPointerLong & bufferMask));
x1 = *(delayBuffer + ((readPointerLong + 1) & bufferMask));
outputSample = x1 + (x2 - x1) * fraction;
Using the hermite polynomial is a little more involved, temporary variables c0 – c4 are used to make the code easier to read. This is using James McCartney’s code from musicdsp.org:
When processing samples in blocks, it is necessary to provide an interpolated delay time parameter for every sample. We can do this by simply calculating the change in parameter value for each sample as follows.
float currentDelayTime;
void Delay(float *input, float *output, float delayTime, long samples)
{
float delayTimeIncrement;
long i;
delayTimeIncrement = (delayTime - currentDelayTime)/samples;
for(i = 0; i < samples; i++)
{
// DELAY CODE GOES HERE USING currentDelayTime
currentDelayTime = currentDelayTime + delayTimeIncrement;
}
currentDelayTime = delayTime;
}
This takes care of smoothing out parameter change between blocks, however, additional smoothing could be needed for external controllers. A mouse position can be updated as slowly as 60 times a second. Other external sources (knobs, MIDI, network) can also have noise or jitter. Generally it is necessary to design a smoothing filter that works for each source, smoothing the jitter, but quick enough to feel responsive. A simple low pass filter is one common approach.
The coefficient (0.99) can be varied for responsiveness. At 48k, this comes within 1% of the new control position in just under 10ms.
Dopper Shift Limiting
The other factor one might consider, especially when there is a large range for the delay time, is to limit the change of delay time per sample. If the delay time moves quickly across a large time span (i.e. from 10ms to 5s), it can create high frequency doppler shift. In this case, it is helpful to limit the change by sending it through a saturation function (a sigmoid, s shaped, function). In the following code this is done with atan().
The factors 0.25 and 4.0 are chosen here to allow the delay time change to be fairly linear under 1.0 (1 sample of delay time change per 1 sample played), but increasingly limited as so that the delay time never changes more than 2π per sample. This factor is a doppler shift of about 2.5 octaves. Changing the factors around atan() will change this doppler shift limit.
Delay effect design draws on a number of previously explored techniques. Wavetable interpolation will be used to read samples from the delay. Compression and saturation will be used to maintain the gain within the feedback loop. Filtering will be used to remove high or low frequencies from the echoes. A delay starts with a fairly straightforward design, but becomes complex with the integration of these techniques, and gathers its individual character as design decisions are made.
Design
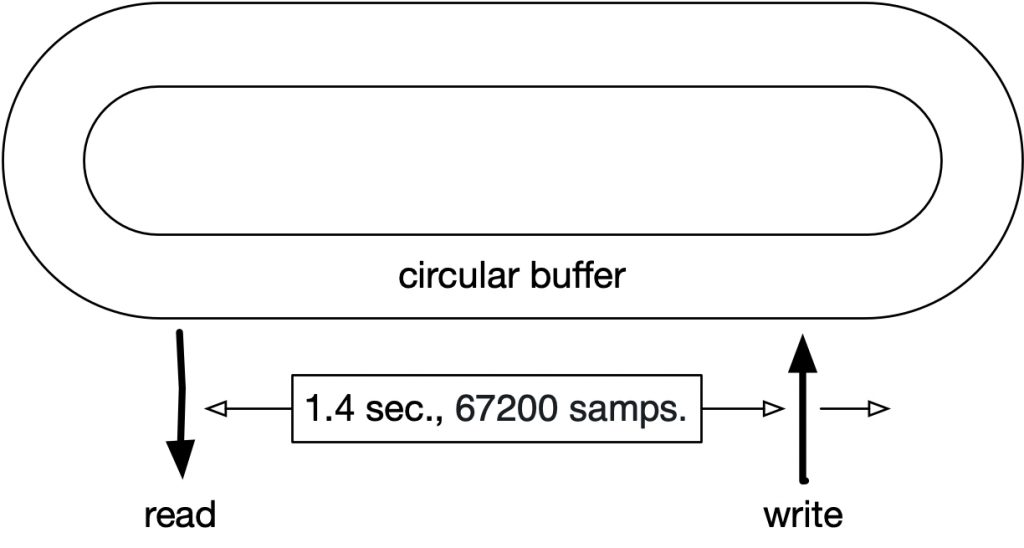
To create a delay, we need a sample buffer to hold audio until the delayed signal is played. Input samples will continually be written to this buffer, and output samples will continually be read from this buffer. To do this, point the input sample to a starting location, write the sample, and move the input pointer one sample over. The output pointer is positioned relative to the input pointer, with the delay time in samples separating them. If the delay time is 1.4 seconds, and the sample rate is 48k, the separation between input and output pointer is 1.4 x 48000 or 67200 samples.
If unlimited storage is available, the input pointer and output pointer could move indefinitely. A large storage space could be used: a 1TB flash drive could run a delay at 48k/32 bit for 30 days before running out of memory. However, much smaller and faster memory is more typically used for the sample buffer. Because of this, it is typical to reuse the memory – after the input pointer reaches the last sample, it resets to the first sample. This is called a circular buffer. A large enough buffer is needed for the longest delay time desired. For a 42 second delay, with a sample rate of 48k, enough memory to hold 42 * 48,000 or 2,016,000 samples is needed. For sample addressing convenience (discussed later), we will use the nearest power of 2. In this case it is 2^21 or 2,097,152 samples.
Implementation
On embedded processors, it is typical to use physical memory for the circular buffer. In that case we could just use an array declaration. For a plugin or app, memory allocation is necessary. The functions malloc (C) or new (C++) would be used to create the sample buffer.
// C example of delay memory allocation
float *delayBuffer;
long delaySize, delayMask;
delaySize = 2097152;
delayMask = delaySize - 1;
delayBuffer = (float *)malloc(delaySize * sizeof(float));
Pointer arithmetic is used to determine the memory location to write the input sample. After the sample is written, writePointer is moved one sample. In the diagrams above writePointer is incremented. However, it makes our program simpler if writePointer is decremented. This is because readPointer is calculated by adding the delay in samples to writePointer. After decrementing, a bitwise AND is used to maintain the circular buffer (to make sure writePointer is between 0 and delaySize).
// C example of putting sample in delayBuffer,
// decrementing and wrapping writePointer
*(delayBuffer + writePointer) = inputSample;
writePointer--;
writePointer &= delayMask;
To complete our echo, the delayed sample should be read out using readPointer. Its position is relative to writePointer: readPointer = writePointer + (delayTime * sampleRate) . As with writePointer, a bitwise AND will keep readPointer between 0 and delaySive.